

꾸스코딩
[논문리뷰] CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering, EMNLP'24 본문
[논문리뷰] CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering, EMNLP'24
꾸스코딩 2025. 2. 9. 15:23안녕하세요 :)
2번째 논문을 들고 돌아왔습니다.
https://arxiv.org/abs/2409.19753
CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
Recent studies have explored the use of Large Language Models (LLMs) with Retrieval Augmented Generation (RAG) for Knowledge Graph Question Answering (KGQA). They typically require rewriting retrieved subgraphs into natural language formats comprehensible
arxiv.org
오늘 소개해드릴 논문도 제목부터 한 번 톺아보도록 하죠!!
Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
▶ Chain-of-Thought
해당 용어는 정답을 도출하는 사고의 흐름을 프롬프트로 LLM에게 제공하는 기법입니다.
아마 프롬프트에 익숙하시다면 한 번쯤 들어보셨을 용어일 것 같네요!
▶ Enhanced Knowledge Rewriting
직독직해하면 향상된 지식 재작성(?)인 것 같은데요. 아직 제목만 봤을땐 감이 잘 안오네요.
뭔가 지식을 알아듣기 쉽게 재작성하는 내용을 이 논문이 담고있지 않을까 예상해봅니다.
▶ Complex Knowledge Graph Question Answering
KGQA라는 task는 첫 번째 포스팅에서 설명을 드렸는데요.
다시 한번 설명드리자면, 지식 그래프의 정보들을 활용하여 질문에대한 답변을 반환하는 task입니다.
그런데 앞에 "complex"라는 키워드가 붙었으니 아마 "복잡한" 질문들을 다루고자하는 내용인 것 같네요!
Introduction (Background, Motivation, Contribution)
Background는 해당 논문을 이해하기위해 논문에 작성되어있는 간단한 개념들을 정리한 파트입니다.
Motivation은 기존 연구가 어떻길래 해당 연구가 필요한지 즉, 연구 동기에대해 정리한 파트입니다.
Contribution은 motivation을 어떻게 해결하였는지에대한 내용을 정리한 파트입니다.
◼︎ Background
- KG-Augmented LLMs for KGQA (KGQA를 RAG pardigm으로 해결하고자!)
- KG로부터 질문 관련 triples retrieve
- CoT와 RAG 함께 사용하여 복잡한 질문 해결하고자!
- Preference Alignment for LLMs on QA
- Preference Alignment의 목표: LLM fine-tuning으로 human preference와 align되도록
- QA task에 적용된 연구들도 꽤 잇음 !
- 기존 Knowledge Rewritting 연구
- Simple Linear Concatenation (Triple): subject + relation + object 이렇게 이어서 triple-form text로 유지
- KG-to-Text: Free-from text
- Summary: 질문과 관련된 정보만 사용하고자 요약 생성
◼︎ Motivation

- LLM은 여전히 knowledge intensive task를 잘 해결 못함 → b/c hallucination
- 원인) factual inaccuracy & outdated knowledge
- 보완 방법 : RAG(Retrieval-Augmented Generation ✳︎KGQA의 RAG pardigm에서는 question-related subgraph→ nautral language로 변환 필요
- 기존 knowledge rewritting 방법들은 ..
- Redundancy or ommision: Triple & KG-to-Text
- Semantic mismatch
⇒ 불필요한 정보와 중요한 디테일들을 생략하거나 질문의 의미와 align되지 않는다는 한계
◼︎ Contribution
- CoTKR(Chian-of-Thought enhanced Knowledge Rewriting) framework 제안
: CoT를 통해 knowledge representation의 quality 향상 도모 - 학습 전략 PAQAF(Preference Alignment from Question Answering Feedback) 제안
: Rewriter와 QA model 간의 gap 완화하기 위해서!
Methods
해당 파트에서는 방법론에대해 설명하는 파트입니다.

1️⃣ Chain-of-Thought Enhanced Knowledge Rewriting
- KG로부터 질문과 관련한 subgraph retrieve
- CoTKR을 이용하여 retrieve 결과 contextual knowledge로 변환
a. Reasoning: 질문 decompose & reasoning trace 생성
b. Summarization: current reasoning trace 기반으로 관련 지식들 요약
⇒ $x_{t,r}+1$ 과 $x_{t,k}+1$ 연결되어 step t의 knowledge represenation 구성
c. 위 정보들을 기반으로 QA LLM이 CoT를 기반으로 answer 생성

2️⃣ Training Framework for CoTKR
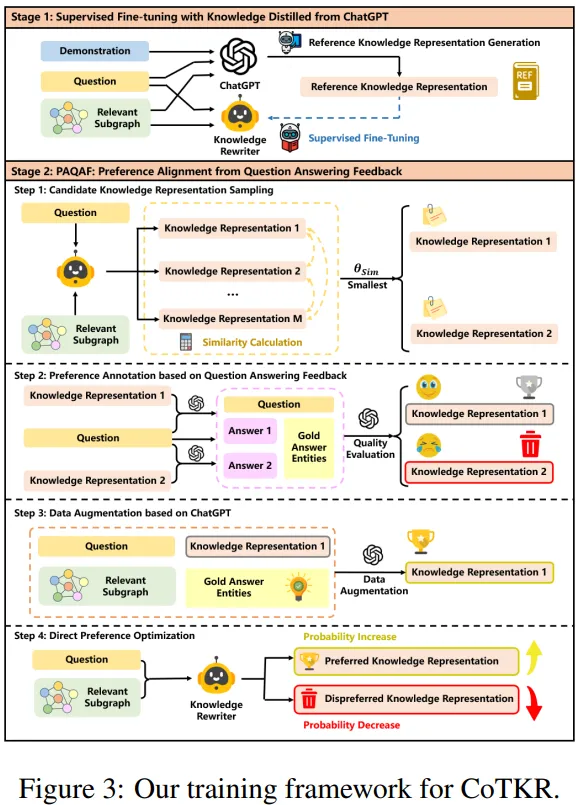
[1] Supervised Fine-tuning with Knowledge Distilled from ChatGPT

① Reference Knowledge Represenation Generation
- Data generator로 ChatGPT 사용
- Question-relevant subgraph $G'$를 질문과 함께 simple linear concatenation하여 input prompt $x$ 구성
- 궁극적으로 ChatGPT가 several examples(=demonstration)와 input $x$를 기반으로 reference knowledge represenation $k$ 생성

② Supervised Fine-tuning
- $R_θ$ : knowledge rewriter
- 해당 모델이 $x_i$를 기반으로 $k_i$ 생성이 목표

[2] Preference Alignment from Question Answering Feedback (PAQAF)
목표 knowledge rewriter와 QA model 사이의 gap 완화
① Candidate Knowledge Representation Sampling

- 질문 q와 corresponding subgraph $G'$를 input
- Knowledge Rewriter $R_θ$로부터 candidate knowledge representation $M$개 샘플링
② Preference Annotation based on QA Feedback

- 위에서 샘플링한 candidate knowledge에서 semantic difference가 가장 큰 knowledge 2개 선택 → $(k_1, k_2)$
- QA 모델로 하여금 $k_1, k_2$에 대해 각각 정답 $a_1, a_2$ 생성
- 생성된 정답들에 대하여 ChatGPT가 평가 진행
- Preferred knowledge : $k^+$
- Dispreferred knowledge : $k^-$
③ Data Augmentation based on ChatGPT
목표 Preferred knowledge represenation의 quality 향상 + 학습 데이터의 다양성 향상

- ChatGPT로 하여금 $k^+$ paraphrase하도록 함 & 정답 entity도 제공
⇒ 이에따라, ChatGPT가 정답 entity와 관련된 knowledge를 정리하고 rewritten knowledge가 key evidence를 포함할 것을 보장 가능 - Paraphrased Knowledge = $k^{++}$
- Preference dataset : $P_N = \{ (x_1, k^{++}_1, k_1^-), (x_2, k^{++}_2, k_2^-), ..., (x_N, k^{++}_N, k_N^-)\}$
④ Direct Preference Optimization

- Rewriter $R_θ$ 에 DPO 적용하여 $R_{θ^*}$ 형성
- 아래 목적함수를 minimize하는 방향으로!

Experiments
해당 파트에서는 실험 세팅 및 결과에대해 설명하는 파트입니다.
- 데이터셋
- GrailQA: trian/dev/test (44,337/6,763/13,231)로 구성 & trian/dev 데이터셋은 SPARQL query가 제공되지만, test는 질문만 존재!
- GraphQuestions: trian/test (2,771/2,395)로 구성 & Freebase 기반이며 SPARQL query와 정답 entities 제공
- 사용 LLM
- Knowledge rewrite: Llama-2(7B), Llama-3(8B), ChatGPT
- QA task: ChatGPT, Mistral(7B)
- Baselines: 기존 knowledge-rewrite 방법론들과 비교(triple, kg-to-text, summary)
- Retrieval Methods
- 2-hop (head entity 기준으로 2hop subgraph로부터, question과의 유사도 기반 30 triples 남김)
- BM25
- Ground Truth Subgraph (GS): Golden subgraph
- Evaluation Metrics : Acc, Recall, EM
- Main Result

🐹 SUM UP
2번째 논문이 마무리 되었습니다 :)
해당 논문은 retreiver 쪽을 건드리지 않고, 우선 정보를 잘 뽑아왔다는 가정 하에 structural information을 어떻게 잘 처리할지에대한 연구를 보여준 논문이었습니다. 보통 이 부분에대한 연구가 부족한데 해당 부분을 잘 긁어준 논문이지 않나 싶습니다.
또한, KGQA에서 DPO를 쓰는 논문을 이 논문을 통해 처음 접하게 되어 꽤 흥미로웠습니다.
그러나, 생성한 데이터에대한 필터링 혹은 검증이 조금 부족하다고 느껴지기도 했는데, DPO로 해결한건가?라는 생각도 들었습니다.


